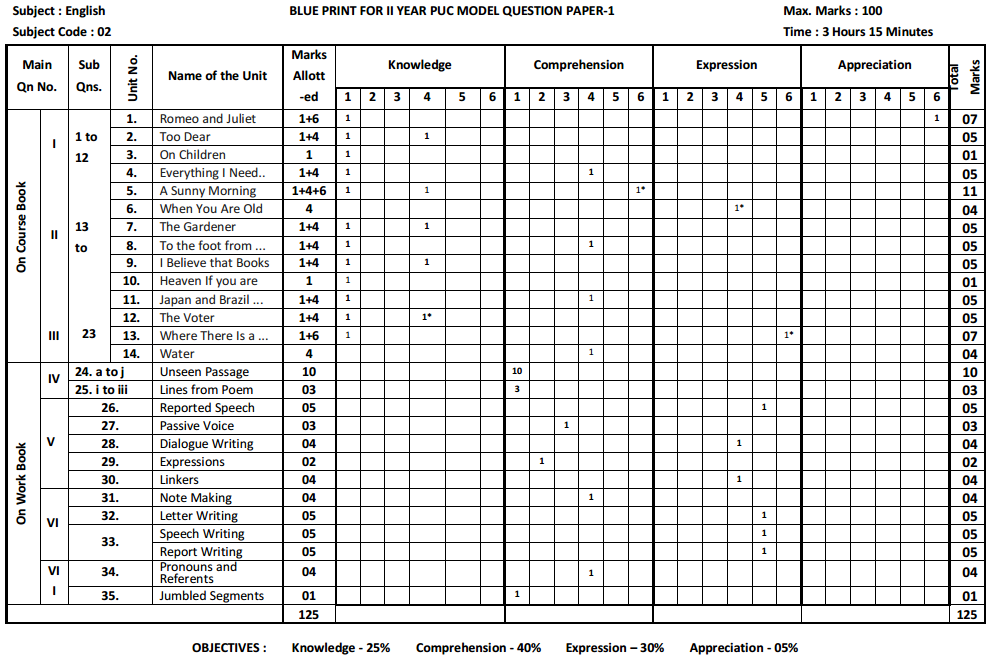
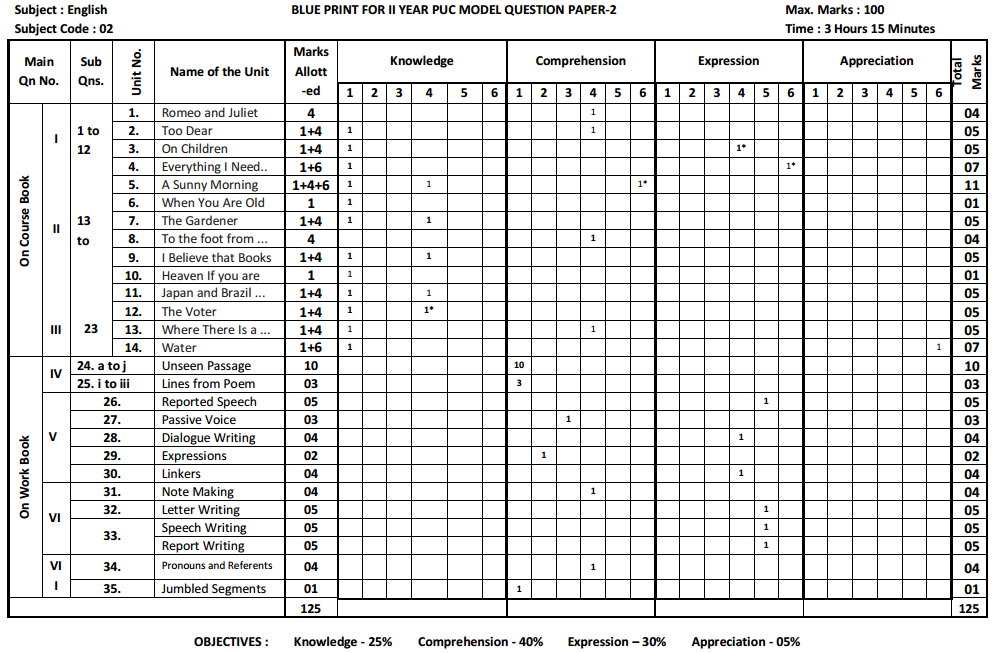
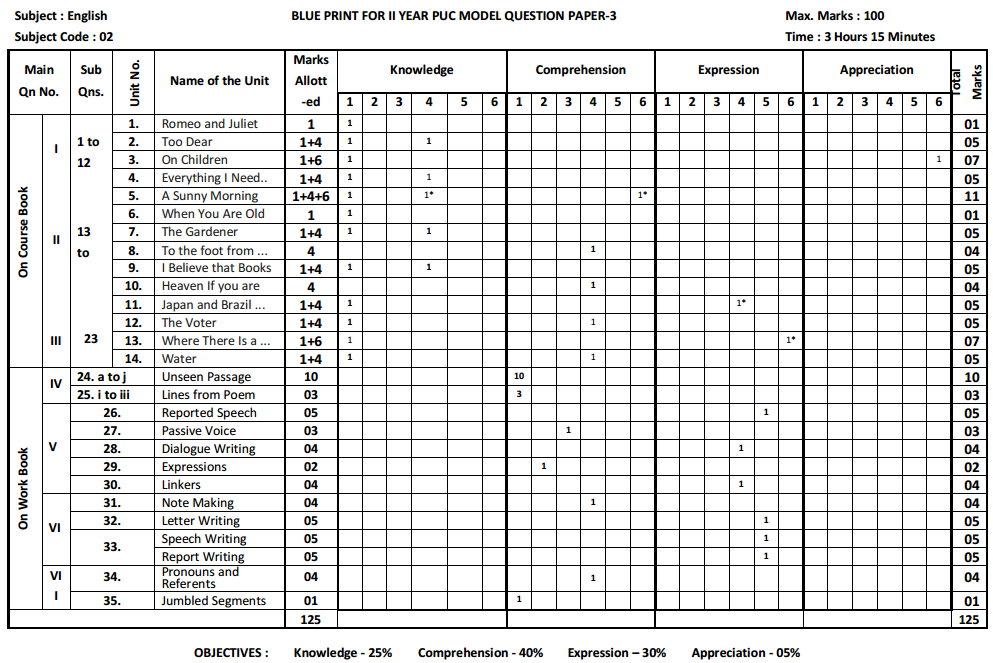
Karnataka 2nd PUC Sociology Question Bank Chapter 1 Making of Indian Society and Demography
You can Download Chapter 1 Making of Indian Society and Demography Questions and Answers, Notes, 2nd PUC Sociology Question Bank with Answers Karnataka State Board Solutions help you to revise complete Syllabus and score more marks in your examinations.
2nd PUC Sociology Making of Indian Society and Demography One Mark Questions and Answers
Question 1.
How is the term Demography derived?
Answer:
The term Demography is derived from two Greek words i.e. demos (people) and graphein (describe), implying the description of people.
Question 2.
What is Demography?
Answer:
Demography is the systematic study of population.
Question 3.
Name any one type of Demography.
Answer:
Formal Demography.
Question 4.
Give one major characteristic of Demographic profile of India.
Answer:
Size and Growth of India’s Population.
Question 5.
Mention sex ratio of India according to 2011 census.
Answer:
940.
![]()
Question 6.
Which district in Karnataka is Selected to Implement Beti Padavo and Beti Bachavo Programme?
Answer:
Vijyaypura District.
Question 7.
Name one racial group of India.
Answer:
Negritos.
Question 8.
Give one sub division of Mongoloid race in India;
Answer:
Paleo Mangoloid.
Question 9.
Who introduced Christianity to India?
Answer:
St Thomas and St Bharathaomew.
Question 10.
What is unity?
Answer:
Unity implies oneness, or a sense of we-ness.
Question 11.
Name one basis of diversity in India.
Answer:
Linguistic Diversity.
Question 12.
Name one basis of unity of India.
Answer: Religious unity.
Question 13.
What is National Integration?
Answer:
National integration refers to national unity and a sense of belonging to the nation.
Question 14.
Name anyone challenge to National Integration.
Answer:
Communalism.
![]()
Question 15.
Name any one religious community of India.
Answer: Hindus.
Question 16.
Name any one ancient name of India.
Answer:
Bharathakanda.
Question 17.
What does DEMARU stands for?
Answer:
Data from 2001 census to coin another acronym – DEMARU – where D stands for daughter and MARU stands for killing. In English “E” will denote elimination. Punjab, Hariyana, Himachal Pradesh & Gujarath, Maharashtra as DEMARU states, where the sharp decline in the Juvenile sex ratio.
Question 18.
Which European colonial group first entered India?
Answer:
Portuguese.
Question 19.
Expand the UNPF
Answer:
United Nations Population Fund.
Question 20.
Expand the Abrivation BIMARU
Answer:
Bihar, Madhya Pradesh, Rajasthan and Uttar Pradesh.
Question 21.
Define formal Demography.
Answer:
Formal demography is primarily concerned with the measurement and analysis of the components of population change. Its focus is on quantitative analysis for which it has a highly developed mathematical methodology suitable for forecasting population growth and changes in the composition of population.
Question 22.
Define social Demography.
Answer:
Social demography, on the other hand, enquires into the wider causes and consequences of population structures and change. Social demographers believe that social processes and structures regulate demographic processes; like sociologists, they seek to trace the social reasons that account for population trends.
Question 23.
In which year first census was conducted.
Answer:
1867-72.
Question 24.
Which is the oldest civilization of India.
Answer:
Indus valley civilization.
Question 25.
In which was year Kannada language has declared as one of the classical languages.
Answer:
2008.
Question 26.
What is the total population of Karnataka according to 2011 census?
Answer:
6,10,95,297.
Question 27.
What is the sex ratio of Karnataka according to 2011 census?
Answer:
973.
![]()
Question 28.
Which is the most populated district in Karnataka.
Answer:
Bangalore District.
Question 29.
Which district has Highest Sex Ratio in Karnataka? ‘
Answer:
Udupi District (1094).
Question 30.
Which district has Lowest Sex Ratio in Karnataka?
Answer:
Bangalore District (916).
Question 31.
What is the density of Karnataka according to 2011 census?
Answer:
319.
Question 32.
Which district in Karnataka registers Highest density?
Answer:
Bangalore District (2985).
Question 33.
Which district in Karnataka registers Lowest density?
Answer:
Kodagu District (134).
Question 34.
Which district has recorded highest SC population in Karnataka?
Answer:
Kolar District.
Question 35.
Which district has recorded highest ST population in Karnataka?
Answer:
Raichur District.
Question 36.
Which district in Karnataka has retained highest literacy rate?
Answer:
Dhakshina Kannada (88.57).
Question 37.
Which district in Karnataka has retained lowest literacy rate?
Answer:
Yadagiri(51.83).
Question 38.
What is the total literacy rate of Karnataka in 2011?
Answer:
75.39%.
Question 39.
What is Sex Ratio?
Answer:
Number of females for 100 male population.
Question 40.
State a Reason for Imbalance in Sex Ratio.
Answer:
Sex selective abortion.
Question 41.
Which year is considered as demographic divide?
Answer:
1921.
Question 42.
How many languages were recognized by Indian constitution as official languages?
Answer:
22.
Question 43.
Mention any one Indo-Aryan language
Answer:
Hindu.
Question 44.
Mention any one Dravidian Language.
Answer:
Kannada
Question 45.
Mention any one Austric Language
Answer:
Mundari.
![]()
Question 46.
In which year Government of India declared Kannada as one of the classical language?
Answer:
2008.
Question 47.
Which is the oldest water dispute in the world?
Answer:
Cauvery water dispute.
2nd PUC Sociology Making of Indian Society and Demography Two Marks Questions and Answers
Question 1.
Define Demography.
Answer:
Demography studies the trends and processes associated with population including – changes in population size; patterns of births, deaths, and migration; and the structure and composition of the population, such as the relative proportions of women, men and different age groups.
Question 2.
Give two major characteristics of Indian Demographic profile.
Answer:
- Size and Growth of Population.
- The declining sex ratio.
Question 3.
Mention any two factors responsible for decline of child sex ratio.
Answer:
Sex selective Abortions, Neglect of Girls in an Infancy.
Question 4.
Mention any two racial groups of India.
Answer:
Negritos and Mongoloids
Question 5.
Name two difficulties to the process of Aryanzation.
Answer:
- Tribal groups refused to be absorbed.
- Special problem posed by strong ethnic groups.
![]()
Question 6.
What does DEMARU stands for?
Answer:
Data from 2001 census to coin another acronym – DEMARU – where D stands for daughter and MARU stands for killing. In English “E” will denote elimination. Punjab, Hariyana, Himachal Pradesh & Gujarath, Maharashtra as DEMARU states, where the sharp decline in the Juvenile sex ratio.
Question 7.
Define national Integration.
Answer:
National integration refers to national unity and a sense of belonging to the nation.
Question 8.
What is Regionalism?
Answer: Regionalism refers to an extreme loyalty or love to a particular region which may undermine the interest of the nation.
Question 9.
What is communalism?
Answer:
Communalism is the antagonism practiced by the members of one community against the people of community and religion.
Question 10.
What is Iinguism?
Answer:
Linguism implies one-sided love and admiration towards one’s language and a prejudice and hatred towards others’ languages.
Question 11.
Give two measures to strengthen national integration.
Answer:
- Reorganization of syllabus
- conductiong community programmes.
Question 12.
State any two dravidian language.
Answer:
Tamil and Kannada.
Question 13.
State any two Indo – Aryan languages.
Answer:
Sanskrit and Hindu.
Question 14.
State any two Austric languages.
Answer:
Mundari and Santhali.
Question 15.
State any two Tibeto – Burman languages.
Answer:
Bodo and Ladaki.
Question 16.
Mention any two classical languages of India.
Answer:
Sanskrit and Tamil.
![]()
Question 17.
Mention any two threats to national Integration.
Answer:
Communalism and Regionalism.
Question 18.
State any two forms of regionalism.
Answer:
- Demond for a separate Nation from India.
- Demond for a separate State within India
Question 19.
Why India is regarded as museum of languages?
Answer:
India is a land of many languages and it has been called as a ‘museum of languages’.
Question 20.
What is demographic Dividend?
Answer:
Demographic dividend refers to demographic or population advantage which is obtained due to numerical domination of the young people in the population. It is an advantage due to less dependency ratio.
Question 21.
What is dependency ratio?
Answer:
Dependency ratio means children less than 14 years and people above 65 years are considered as to be dependent on the rest of the population. In simple terms the ratio of the combined age group 0-14 years plus 65 years & above to the 15-65 years age group is referred to as the total dependency ratio.
2nd PUC Sociology Making of Indian Society and Demography Five Marks Questions and Answers
Question 1.
Explain the racial groups classified by B.S. Guha.
Answer:
B.S. Guha who identified six major racial elements in the population of India:
- Negrito
- Proto-Australoid
- Mongoloid
- Mediterranean
- Western Brachycephals .
- Nordic
In the south, the Kadar, the Irula, and the Paniyan, and in the Andaman Islands, the Onge and Jarwas of the Andamanese have definite Negrito characteristics. Some traits of this group are found among the Angami Naga and the Bagadi of the Rajmahal hills. On the western coast there are some groups with pronounced Negrito traits, but they perhaps represent later arrivals, who came to India with the Arab traders.
The Proto-Australoid group is numerically more significant; most of the tribes of middle India belong to it. These were the people described by the Indo-Aryans as Anas, Dasa, Dasyu, and Nishad – all derogatory terms. The Mongoloid group is sub-divided into two branches – Paleo- Mongoloid and Tibeto-Mongoloid. Tribal groups in the Himalayan region and those in the north-east are of Mongoloid stock. Some Mongoloid features are seen in the non-tribal population of the eastern States – Assam, West Bengal, Manipur, and Tripura.
The Western Brachycephals (sub-divided into the Alpinoid, Dinaric, and Armenoid groups), Alpinoid and Dinaric characteristics are seen in some groups of northern and western India; the Parsis belong to the Armenoid section. The Mediterraneans are associated with the Dravidian languages and cultures. The Nordics were the last major ethnic element to arrive in India and make a profound impact on its culture and society. But before they came a unique civilization had slowly developed in India. It is known as the Indus Valley Civilization.
![]()
Question 2.
Write note on the processes of Aryanization.
Answer:
They were essentially a pastoral people with a flair for poetry, philosophical speculation, and elaborate rituals. They regarded themselves as superior and tended to look down upon the earlier inhabitants of the land, for whom they coined several derogatory terms. They were required to marry within their own group, i.e., practise endogamy, and had some elementary notions of ritual purity and pollution which governed their physical contacts and commensal – inter-dining – relations with others. This led to the origin of the Vamas and also of Jati (caste). Commensality and sexual relations within different tribal groups and earlier ethnic groups were governed by customary norms and taboos, and the advent of the Indo-Aryans brought in refinements and complexities in them.
The Indo-Aryans were divided into three groups – the Rajanya (warriors and the aristocracy), the Brahmana (priests), and the Vaishya (cultivators). These were Dvija (twice-born) groups
born first at physical birth and a second time when initiated into Varna status. The Shudras were the fourth Vama; they were from outside the Indo-Aryan group and were perhaps the progeny of unions between the Indo-Aryan and the Dasa (the pre-Aryan .inhabitants of the land). They emerged as cultivators, but were denied twice – bom status. Outside the four-fold vertical Vama structure, there was a fifth group – Avarna or the Pancham – whose ethnic status was so low and their occupations so degraded and polluting that any physical contact with them was prohibited for the twice-born and the Shudra.
The process of Aryanization of the sub-continental traditions was neither smooth nor complete. Its earlier phase was characterized by considerable cultural conflict and warfare. Much Accommodation and Compromise were also taking place.
This necessitated greater harmony with the older inhabitants; in any case, some kind of synthesis between them was already taking place. As a result the non-Aryans adopted some elements of Indo-Aryan ritual and their philosophy of social organization, while retaining their own ethnic and regional identities. Pluralism was being stabilized and a cultural mosaic being formed.
Question 3.
Explain the nature of diversities in India.
Answer:
The term Diversity denoting collective differences so as to find out dissimilarities among the people: geographical, religious, linguistic etc. Thus all these differences presuppose collective differences or prevalence of variety of groups and culture. Indian society is characterized by unity as well as diversity.
The Nature of Diversities in India
Primarily there are major four types of diversities in India, which are;
- Regional Diversities
- Linguistic Diversities
- Religious Diversities
- Cultural and Ethnic Diversities
(1) Regional Diversities: It is evident that there are extreme regional diversities in its geographic features. Indian territory contains huge mountains, thick forests, numerous rivers and etc. It is only in India that there are different regions, different types of climates and the temperatures. India is a vast country. From the Himalayas in the North to Indian Ocean in the south. There are difference in altitude, temperature, Flora and Fauna. India has every conceivable type of climate, temperature and physical configuration. There is the scorching heat of Rajastan and the biting cold of the Himalayas, Rainfall varies from 1200 to 7.5 cms per year. The result is that India has some of the wettest and driest areas in the world. India also possesses arid desserts and fertile riverine lands, bare and hilly tracts and luxuriant open plain.
(2) Linguistic Diversities: Language is another source of diversity. It contributes to collective identities and even to conflicts. The Indian Constitution has recognized 22 languages in the 8th schedule for its official purposes but as many as 1652 languages and dialects are
spoken in the country. According to Grierson’s Linguistic Survey of India, these languages belong to five linguistic families, namely; Indo-Aryan languages, Dravidian languages, Austric languages, Tibeto – Burman languages and European languages.
- The Indo-Aryan languages including in the Sanskrit, Hindi, Bengali, Marati, Gujarathi, Oriya, Panjabi, Bihari, Rajasthani, Assami, Sindhi and Kashmiri languages spoken by 3/4th of Indian population.
- The Dravidian languages include Tamil, Kannada, Telugu and Malayalam.
- The Austric languages include Mundari, Santhali, Maithili, Dogri and etc.
- Tibeto – Burman languages: Tribal languages and dialects of North and North-East India belong to this category. For example Manipuri, Bodo, Ladiki, Khaki, etc.
- The European languages include English, Portuguese and French. These last two languages are spoken mostly people in Goa and Pondicherry.
This makes language planning and promotion difficult. But the mother tongue does evoke strong sentiments and reactions. As a consequence of this multiplicity, there is considerable bilingualism and administration has to use more than one language. Linguistic diversity has posed administrative and political challenges.
(3) Religious Diversities: There are eight major religious communities in India. Hindus constitute 82.7%, Muslims 11.8%, Christians 2.6%, Sikhs 2%, Buddhists 0.7%, Jains 0. 4%, Zoroastrians 0.3%, and Jews 0.1 %. Each major religion is subdivided along the lines of religious documents, sects, and cults. The Hindus are now broadly divided into Shaivite (worshippers of Shiva), Vaishnavaite (worshippers of Vishnu and his incarnations), Shakta (worshippers of the Mother Goddess in various manifestations. Even among them there are sub – divisions based on doctrinal and ritual differences.
Buddhism was spread widely in India once, it lost its hold in the country of its birth and remained confined only to a few pockets. Jainism too, once held wide sway in India, and though its followers are now numerically small, they are found in both the northern and southern States. They have two main divisions: Digamber-unclothed, and Shwetamber. The Indian Muslims are divided broadly into the Sunni and Shia communities.
Indian Christians are divided into Roman Catholics and Protestants and into many denominational churches. Sikhism is synthesizing religion that emphasizes egalitarianism. Grantha Sahib is the holy book and Amritsar Golden Temple is one of their holy piligrimage. The Parsis are a small community, but they have played an important role in India’s industrial development. The Jewish has been established in India for over a millennium. They also had White and Black divisions and prohibition on inter-marriage and inter-dining, but they all worshipped in the same synagogues. The Jati-like restrictions are much less in Bombay and Cochin, to where many Jews have migrated.
(4) Cultural and Ethnic Diversities: Another important source of diversity is the cultural diversity. The people differ considerably in their social habits. Cultural difference varies from state to state. The conflicting and varying shades of blood, strains, culture, and modes of life, the character, conduct, beliefs, morals, food, dress, manners, social norms, Socio-Religious customs, rituals and etc. causes cultural and ethnic diversities in the country. Dr. R.K. Mukherji rightly said that “India is a museum of cults and customs, creeds and culture, faiths and tongues, racial types and social systems”. Another important source of diversity is the cultural identity of particular communities and region.
![]()
Question 4.
Explain the unity in India.
Answer:
In India aspects of Diversity is as follows as :
(1) Regional Unity: The Natural boundaries provide India a. geographical unity. In ancient times India was known as Bharatavarsha, Bharathakanda, Jambudweepa. This symbolizes the significance of historical unity. The very name “Bharatavarsha” has occupied an important place in the minds of poets, political philosophers, and religious thinkers. Each of them has conceived of the country as a single expanse from the Himalayas to Kanyakumari, a country ruled by one king Bharatha. The concept of Mother India also indicates the realization of geographical unity.
(2) Linguistic Unity: Despite the presence of number of languages, India also possesses lingual unity. Sanskrit as a common base of Indian languages provides the basis of unity as a result of which the linguistic multiplicity has been solved. Simultaneously Sanskrit became the language of Hindu culture and all classics were composed in this language, which demanded reverence and respect. People may speak different languages in different regions but they have common language of Engl ish and Hindi to communicate with each other. The formation of linguistic states and using regional languages as medium of teaching at schools, colleges and universities are the products of Independence.
In 2004 the govt, of India declared that languages that met certain requirements could be accorded the status of a classical language in India. Tamil (2004), Sanskrit (2005), Kannada (2008), Telugu (2008), Malayalam (2013) and Oriya (2014) are declared as classical languages of India. Thus it is an effort to restore linguistic heritage of India.
(3) Religious Unity: In spite of the religious diversities, it possesses religious unity. The feelings of each religious groups are the same, each accepts the truth of immortality of > soul, temporary nature of world, belief in rebirth, the doctrine of karma, Salvation, Contemplation etc., There may be differences in the way these elements are treated but each religion preaches a fundamentally single religious faith and shares a belief in purity ; and values of life in respect of belief in unseen power, benevolence, piety, honesty and liberality, with every religious faith. The worshippers may visit different centres of pilgrimage, but all have a common goal of “Earning religious merit by visiting a sacred place”. India is the sacred land not only for the Hindus but also for Sikhs, Jains and Buddhists. The Muslims and Christians too have several sacred centres of pilgrimage in India.
(4) Cultural Unity: In art and architecture, dress and food, literature, music and dance, sports and cinema, medicine and technology there was a fusion of style and the emergence
of new forms which were the result of their combined efforts. Thus it became apparently clear from the above account that running through various diversities. India has been helped both by nature and nurture, by her geographical condition and historical experiences, by her religious ethics, and political ideas. To realize a unity to perceive, preserve and strengthen the thread of basic unity which makes India a fine example of unity in diversity, transcending birth, caste, language, ethnicity and religious groupings to establish a big society and a big nation.
Modem education, the development of a network of transport and communications, industrialization and urbanization provided new bases for unity.
![]()
Question 5.
Discuss briefly the challenges to National Integration.
Answer:
There are many challenges to national integration. They are as follows:
- Regionalism
- Communalism
- Linguism
- Extremism and Terrorism
(1) Regionalism: Regionalism is expressed in the desire of people of one region to promote their own regional interest at the expense of the interests of other regions. It has often led to separatism and instigated separatist activities and violent movements. It has also gained tremendous momentum during the recent years because it is exploited by the selfish politicians Thus, regionalism has challenged the primacy of the nationalistic interests and undermines national unity. Regionalism assumed mainly four forms.
(2) Communalism: Communalism is the antagonism practiced by the members of one community against the people of community and religion. Bipin Chandra holds that communalism is the product of a particular society-, economy and polity, which creates problems. Asghar Ali Engineer, Moin Shakir and Abdul Ahmed try to explain communalism as an ideological tool for propagation of economic and political interests. According to them, it is an instrument in the hands of the upper class to concentrate power by dividing people. The elites strive to maintain a status quo against transformation by dividing people on communal and religious lines.
(3) Linguism: Linguism implies one-sided love and admiration towards one’s language and a prejudice and hatred towards others’ languages. India is a land of many languages and it has been called as a ‘museum of languages’. Diversity of languages has also led to linguism. It has often been manifested into violent movements posing threat to national integration. Linguistic tensions are prevailing in the border areas which are bilingual.
(4) Extremism and Terrorism: Extremism and terrorism have emerged during the recent years as the most formidable challenges to national integration. Extremism refers to the readiness on the part of an individual or group to go to any extreme even to resort to undemocratic, violent and harmful means to fulfill one’s objectives. In the past India has been facing the problems of terrorism since independence. India has faced this problem in Nagaland (1951), Mizoram (1966), Manipur (1976), Tripura (1980) and West Bengal in (1986).
Terrorism in India is essentially the creation of politics. According to According to Prof. Rama Ahuja there are four types of terrorism India, (1) Khalistan oriented terrorism in Puniab (2) Militants terrorism in Kashmir. (3) Naxalite terrorism in west Bengal, Bihar, Madhya Pradesh, Orissa, Andhra Pradesh Telangana, Maharastra, Uttarapradesh Jharkhand, chattisghad out of 318 district 77 districts are highly Naxal poore districts causing lot of bloodshed in these areas. (4) ULFA terrorism in Assam.
The Khalistan oriented Sikh terrorism was based on a dream of theocratic state, Kashmir militants are based on their separate identity. The Naxalite terrorism is based on class enmity. Terrorism in North Eastern India is based on the identity crisis and the grievance situation. In addition to these factors, corruption, poverty, unemployment/youth unrest, widening gap between rich and poor, which are also the major challenges for national integration.
![]()
Question 6.
Briefly explain the Dr. Sampurnananda committee recommendations to strengthen National Integration.
Answer:
The Central Education Ministry organized a ‘Committee for National Integration’ in 1961 under the Chairmanship of Dr. Sampurnanand. The Integration Committee gave some recommendations to promote and strengthen national integration. Some of them are stated below:
- Re-organization of the syllabi at various levels – primary, secondary, college and university level- to promote national integration.
- Giving due encouragement to extra-curricular activities besides imparting formal knowledge to the students with the intention of promoting national unity.
- Improvement of textbooks helps a great deal in giving a true national perspective to the students. They can be made to understand their rich cultural heritage and feel proud of their nation.
- Conducting community programmes such as mass prayers, mass meetings, speeches by respected leaders, etc., to help to bring the people together.
Apart from the governmental efforts to achieve the goal of national unity various stakeholders such as educational institutions, religious/cultural associations and mass media should involve in chalking out action-based programmes to enhance awareness/dissemination of traditional values among the masses and increase cultural exchange banking on the richness of our cultural heritage and diversity. Special steps should be taken by various interest groups to speed up development of economically and socially backward groups who are the easy victims of violent activities.
Question 7.
Write a note on BIMARU v/s DEMARU.
Answer:
The results of the 2001 census fully validate the diagnosis of India’s population problem in terms of the dominance of BIMARU States (Bihar, MP, Rajastan, UP) accounted for 39% of India’s population, 42% of growth and 48% of the total Illiterate population and the adverse role of these BIMARU states. To take note of the alarming data from 2001 census to coin another acronym – DEMARU – where D stands for daughter and MARU stands for killing. In English “E” will denote elimination. Punjab, Hariyana, Himachal pradesh & Gujarath, Maharashtra as DEMARU states, where the sharp decline in the Juvenile sex ratio.
These states are in the perverse practice of Foeticide. The unholy alliance between Tradition (Son complex) and Technology (Ultra sound etc.) is playing havoc with Indian society pre-birth sex determination tests & sex selective abortion are rampant in these states. During the last decade in Punjab, the sex ratio (0-6 age group) declined from 875 to 793. In Hariyana the sex ratio (0-6 age group) decreased from 879 to 820.
In Maharashtra every single district showed a decline in the Juvenile sex ratio between 1991-2001. In Himachal pradesh from 951 to 845. In Gujarath from 928 to 878. In Chandigarh from 899 to 845 and in Delhi from 915 to 865. Even though an increase in the sex ratio for the total population was 927 in 1991 to 933 to 2001. In contrast the sex ratio of child population (0-6 age group) which was 945 in 1991 decreased to 927 in 2001. In short the girl child (below 6 years) has lost out badly.
The state-level child sex ratios offer even greater cause for worry. As many as six states and union territories have a child sex ratio of under 900 females per 1000 males. Punjab is the worst off with an incredibly low child sex ratio of 793 (the only state below 800), followed by Haryana, Chandigarh, Delhi, Gujarat and Himachal Pradesh. Uttaranchal, Rajasthan, Uttar Pradesh and Maharashtra are all under 925, while Madhya Pradesh, Goa, Jammu and Kashmir, Bihar, Tamil Nadu, Karnataka and Orissa are above the national average of 927 but below the 950 mark. Even Kerala, the state with the best overall sex ratio does not do too well at 963, while the highest child sex ratio of986 is found in Sikkim.
![]()
Question 8.
What is Demographic Dividend? How it can be utilized?
Answer:
Demographic dividend refers to demographic or population advantage which is obtained due to numerical domination of the young people in the population. It is an advantage due to less dependency ratio. Dependency ratio means children less than 14 years and people above 65 years are considered as to be dependent on the rest of the population. In simple terms the ratio of the combined age group 0-14 years plus 65 years & above to the 15-65 years age group is referred to as the total dependency ratio.
The younger age groups in the age structure is believed to be an advantage for India. Like the East Asian economies in the past decade and countries like Ireland today, India is supposed to be benefitting from a ‘demographic dividend’. This dividend arises from the fact that the current generation of working-age people is a relatively large one, and it has only a relatively small preceding generation of old people to support. But there is nothing automatic about this advantage – it needs to be consciously utilised in the following ways.
a. The demographic advantage or ‘dividend’ to be derived from the age structure of the population is due to the fact that India is one of the youngest countries in the world. In 2020, the average Indian will be only 29 years old, compared with an average age of 37 in China and the United States, 45 in Western Europe, and 48 in Japan. This implies a large and growing labour force, which can deliver unexpected benefits in terms of growth and prosperity.
b. But this potential can be converted into actual growth only if the rise in the working age group is accompanied by increasing levels of education and employment.
c. India is indeed facing a window of opportunity created by the demographic dividend. The effect of demographic trends on the dependency ratio defined in terms of age groups is quite visible. The total dependency ratio fell from 79 in 1970 to 64 in 2005. But the process is likely to extend well into this century with the age-based dependency ratio projected to fall to 48 in 2025 because of continued fall in the proportion of children and then rise to 50 by 2050 because of an increase in the proportion of the aged.
d. This suggests that the advantage offered by a young labour force is not being exploited. Unless a way forward is found, we may miss out on the potential benefits that the country’s changing age structure temporarily offers.
Discuss the Manifestation of Regionalism.
Regionalism assumed mainly four forms:
(i) The Demand for Separate Nation from the Indian Union: The first and most challenging form of Regionalism took was the demand of the people of certain state to succeed from the Indian union and became an independent sovereign states. The first such example was the Tamil community of the state of Madras. The campaign throughout Madras state for the separation of Madras from India and for making it an independent sovereign state of dravidastan. In a similar way Sikhs of Punjab demanded for a separate nation called Khalistan and liberation of Jammu and Kashmir form the Indian union, Insurgency and Secessionist movement in North-Eastern States (Assam, Nagaland, Tripura, Manipur, Meghalaya, Arunachal Pradesh and Mizoram) etc. demand for separate nation.
(ii) Demand for a Separate Statehood: A new form of regionalism has manifested in recent years was the demand for separate statehood in several states of Indian Union, like; Vidarbha states (Maharastra), Telangana, (Andhra Pradesh), Bundelkhand (M.P. and U.P.), Vindhya, Bhojpur and etc. In early 1980s the Jharkhand movement grow much more miltant and the various groups demanding the formation of separate state of Jharkhand, as well in Darjaling, district of West Bengal for Gorkha Land.
(iii) Demand for Full Fledged Statehood: Yet another manifestation of regionalism in India is demand of union territories for full fledged statehood, e.g. Delhi.
(iv) Inter – State Disputes: The first such dispute took place between Karnataka and Maharashtra, Punjab and Haryana. In addition to the above the main disputes are over the sharing of river waters. Over the water of Narmada, Krishna, Kaveri, Bheema and etc. Kaveri water dispute is the oldest water dispute in the world, causing animosity between Karnataka and Tamilnadu frequently.
![]()
2nd PUC Sociology Making of Indian Society and Demography Ten Marks Questions and Answers
Question 1.
Define Demography and Explain the major characteristics of Demographic profile of India.
Answer:
Demography is the systematic study of population. The term Demography is derived from two Greek words i.e. demos (people) and graphein (describe), implying the description of people. The term Demography was coined by Achille Guillard in 1855. Demography studies the trends and processes associated with population including – changes in population size; patterns of births, deaths, and migration; and the structure and composition of the population, such as the relative proportions of women, men and different age groups.
There are different varieties of demography, including Formal demography which is a largely quantitative field, and Social demography which focuses on the social, economic or political aspects of population. All demographic studies are based on processes of counting or enumeration – such as the census or the survey – which involve the systematic collection of data on the people residing within a specified territory.
The American census of 1790 was probably the first modern census, and the practice was soon taken up in Europe as well in the early 1800s. In India, census was conducted by the British Indian government between 1867-72, and regular ten yearly (decennial) censuses have been conducted since 1881. Independent India continued the practice, and seven decennial censuses have been conducted since 1951, the most recent being in 2011. Demographic data are important for the planning and implementation of state policies, especially those for economic development and general public welfare.
The Major Characteristics of the Demographic Profile of India:
- Size and Growth of India’s Population
- Age Structure of the Indian Population
- Sex-Ratio in India
- Birth Rate and Death Rate
- Increasing Literacy Rate of Indian Population
- Increasing Rural-Urban Differences
(1) Size and Growth of India’s Population: India is the second most populous country in the world after China. According to 2011 census India’s population is 121 crores (1.21 billion). Between 1901-1951 the average annual growth rate did not exceed 1.33%, a modest rate of growth. In fact between 1911 and 1921 there was a negative rate of growth of-0.03%. This was because of the influenza epidemic during 1918-19 : 5%of the total population of the country. The growth rate of population substantially increased after independence from British rule going up to 2.2% during 1961-1981. Since then although the annual growth rate has decreased it remains one of the highest in the developing world.
(2) Age Structure of the Indian Population: India has a very young population – that is, the majority of Indians tend to be young, compare to most other countries, the share of the less than 15 age group in the total population has come down from its highest level of 42% in 1971 to 29% in 2011. The share of the 15-60 age group has increased slightly from 53% to 63%, while the share of the 60+ age group is very small but it has begun to increase (from 5% to 8%) over the same period. But the age composition of the Indian population is expected to change significantly in the next two decades. 0-14 age group will reduce its share by about 11% (from 34% in 2001 to 23% in 2026) while the 60 plus age group will increase its share by about 5% (from 8% in 2001 to about 12% in 2026).
(3) The Declining Sex-Ratio in India: The sex ratio is an important indicator of gender balance in the population. The sex ratio is defined as the number of females per 1000 males. The trends of the last four decades have been particularly worrying – from 941 in 1961 the sex ratio had fallen to an all time low of 927 in 1991 before posting a modest increase in 2001.
According to the Census of India 2011 sex ratio has been increased and now it is 940 females per 1000 males. But what has really alarmed demographers, policy makers, social activists and concerned citizens is the drastic fall in the child sex ratio. The sex ratio for the 0 – 6 years age group (known as the juvenile or child sex ratio) has generally been substantially higher than the overall sex ratio for all age groups, but it has been falling very sharply. In fact the decade 1991-2001 represents an anomaly in that the overall sex ratio has posted its highest ever increase of 6 points from the all time low of 927 to 933, but the child sex ratio in 2011 census has dropped from 927 to 914, a plunge of 13 points taking it below the overall sex ratio for the first time.
(4) Increasing Literacy Rate of Indian Population:. Literacy varies considerably across gender, regions, and social groups. As can be seen from Table No. 4, the literacy rate for women is almost 22% less than the literacy rate for men. However, female literacy has been rising faster than male literacy, partly because it started from relatively low levels. Female literacy rose by about 11.2 percent between 2001 and 2011 compared to the rise in male literacy of 6.2 percent in the same period.
Female literacy was 8.9% in 1951 has increased to 65.4 in 2011 male literacy in the same period wan 27.2% has increased to 82.17. In 1951 total literacy rates 18.3% has increased . to 74.04 in 2011.
(5) Increasing Rural-Urban Differences: According to 2011 Census, 68.8% population lives in rural areas while 31.2% people live in urban areas. The urban population has been increasing its share steadily, from about 17.3% in 1951 to 31.2 in 2011, an increase of about two-and-a-half times.
![]()
Question 2.
Explain the development of Christianity and Islam in India.
Answer:
To understand the texture of Indian society we have also to take note of the long presence of Christianity and Islam in the country. Both were influenced by the prevailing ethos and both made some impact on society. Christianity and Islam acquired some special characteristics in the Indian setting. St. Thomas and St. Bartholomew (A.D. 50) are believed to have brought Christianity to India in A.D. 50. When the Portuguese arrived in India, Christianity was found to have spread over seventeen kingdoms of Kerala. It is believed that Kalyan, near Bombay, emerged as a major centre of Christianity. Apart from St. Bartholomew, a specially invited Stoic philosopher – Pantaenus – was preaching at Kalyan.
The early Christians, however, were held in high esteem by the Hindus. Things began to change with the arrival and establishment of the Portuguese in India. When St. Francis Xavier landed in Goa in 1542, it had become a Christian settlement with fourteen churches and over a hundred clergymen. The Italian Jesuit, Roberto de Nobili, who landed in Goa in 1605 and died in Mylapore (Madras) in 1656, communicated with the people in Tamil and other regional dialects. His discussions with the Brahmans were in Sanskrit. De Nobili was keen to get convinced converts from the top of Hindu society to facilitate the rapid spread of Christianity. He avoided contact with Christians of lower caste origins, including their priests. By the end of the seventeenth century De Nobili and his associates had made many converts.
The later development of Christianity in India is better known because of the association of the Church with foreign powers – The Portuguese, Dutch, British, and French. Considerable evangelical and humanitarian work was done by Christian missionaries of diverse nationalities and denominations. Besides Kerala and Tamil Nadu, there are pockets of Christianity in most States of the Indian Union. At least three of the tribal north-eastern States have substantial Christian majorities. Christians have a sizeable presence among the tribals of Chotanagpur too.
Islam first came to India by peaceful methods, often with the encouragement of Hindu rulers. On the western coast, the Balhara dynasty in the north and the Zamorin of the Malabar coast welcomed Muslim traders and encouraged them to settle in places like Anhilwara, Calicut, and Quilon. They could freely build mosques and practice their religion. Arab and Persian immigrants settled down along the coast and married non – Muslim women. This is how the Nawait (Natia) community of Konkan and the Mappilla (Moplah) community of the Malabar coast emerged. The Labbais, on the east coast of Tamil Nadu, are said to have originated from the union of Tamil women with Arabs who were either shipwrecked or exiled from Iraq.
In the thirteenth and fourteenth centuries several missionaries were active in the Punjab, Kashmir, the Deccan, and eastern and western India. What needs to be emphasized is that these missionaries transmitted the message of Islam through love and without the support of the armed might of the State. The sword doubtless won converts but it also evoked hostility; the saints used persuasion and they still have a grateful and devoted following even among non-Muslims.
The socio-political conditions in India had changed by the time Ghazni invaded the country. Infighting between rival kingdoms had weakened Indian resistance. The Muslim rulers were in India not only for the spread of Islam, but had other interests also. Some of them took upon themselves the mission of Islamizing society more seriously than others; discriminatory practices such as the imposition of jizyah (poll tax), in addition to kharaj (tax on land and property), were pursued more vigorously by some rulers, while others were relaxed about them.
Despite long years of Muslim rule the overwhelming majority of the people remained Hindu. The army, state administration, and trade and commerce all depended on the direct and indirect support of the Hindus. Thus, in respect of the hated jizyah we find that it was levied sometimes and then abolished, only to be re-levied by another zealot. In fact, Islam was being Indianized; in the process, it acquired some distinctive characteristics in India. In the realms of art and architecture, philosophy and religion, medicine and other secular knowledge, there was considerable interchange. A composite culture was gradually evolving.
It may be added that Hindu rule was never completely wiped out from India. During the Delhi Sultanate, the Hindu kingdom of Vijayanagar was an impressive power in south. During Mughal times warriors like Rana Pratap refused to surrender; others worked out adjustments which left them considerable internal autonomy.
In Muslim society itself there was internal differentiation. For example, the difference between the Ashraf (those claiming descent from groups of foreign extraction) and Ajlaf (Converts from the lower Hindu castes) had a lower social position, many of the lower groups converted to Islam continued to occupy more or less their old position in society. Some Hindus occupied higher position in the royal courts and were even Generals in the army. The Hindu and Muslim aristocracy was closer. The poorer Muslims could only have the psychological satisfaction of belonging to the religion of the ruling class. But economically and socially they remained backward and exploited. The Muslim rulers of India understood the value of communal amity and realized the importance of inter community tolerance and understanding.
![]()
Question 3.
Define diversity and explain types of diversity in India.
Answer:
The term Diversity denoting collective differences so as to find out dissimilarities among the people: geographical, religious, linguistic etc. Thus all these differences presuppose collective differences or prevalence of variety of groups and culture. Indian society is characterized by unity as well as diversity.
The Nature of Diversities in India
Primarily there are major four types of diversities in India, which are;
- Regional Diversities
- Linguistic Diversities
- Religious Diversities
- Cultural and Ethnic Diversities
(1) Regional Diversities: It is evident that there are extreme regional diversities in its geographic features. Indian territory contains huge mountains, thick forests, numerous rivers and etc. It is only in India that there are different regions, different types of climates and the temperatures. India is a vast country. From the Himalayas in the North to Indian Ocean in the south. There are difference in altitude, temperature, Flora and Fauna. India has every conceivable type of climate, temperature and physical configuration. There is the scorching heat of Rajastan and the biting cold of the Himalayas, Rainfall varies from 1200 to 7.5 cms per year. The result is that India has some of the wettest and driest areas in the world. India also possesses arid desserts and fertile riverine lands, bare and hilly tracts and luxuriant open plain.
(2) Linguistic Diversities: Language is another source of diversity. It contributes to collective identities and even to conflicts. The Indian Constitution has recognized 22 languages in the 8th schedule for its official purposes but as many as 1652 languages and dialects are spoken in the country. According to Grierson’s Linguistic Survey of India, these languages belong to five linguistic families, namely; Indo-Aryan languages, Dravidian languages, Austric languages, Tibeto – Burman languages and European languages.
- The Indo-Aiyan languages including in the Sanskrit, Hindi, Bengali, Marati, Gujarathi, Oriya, Panjabi, Bihari, Rajasthani, Assami, Sindhi and Kashmiri languages spoken by 3/4th of Indian population.
- The Dravidian languages include Tamil, Kannada, Telugu and Malayalam.
- The Austric languages include Mundari, Santhali, Maithili, Dogri and etc.
- Tibeto – Burman languages: Tribal languages and dialects of North and North-East India belong to this category. For example Manipuri, Bodo, Ladiki, Khuki, etc.
- The European languages include English, Portuguese and French. These last two languages are spoken mostly people in Goa and Pondicherry.
This makes language planning and promotion difficult. But the mother tongue does evoke strong sentiments and reactions. As a consequence of this multiplicity, there is considerable bilingualism and administration has to use more than one language. Linguistic diversity has posed administrative and political challenges.
(3) Religious Diversities: There are eight major religious communities in India. Hindus constitute 82.7%, Muslims 11.8%, Christians 2.6%, Sikhs 2%,-Buddhists 0.7%, Jains 0. 4%, Zoroastrians 0.3%, and Jews 0.1%. Each major religion is sub – divided along the lines of religious documents, sects, and cults. The Hindus are now broadly divided into Shaivite (worshippers of Shiva), Vaishnavaite (worshippers of Vishnu and his incarnations), Shakta (worshippers of the Mother Goddess in various manifestations. Even among them there are sub – divisions based on doctrinal and ritual differences.
Buddhism was spread widely in India once, it lost its hold in the country of its birth and remained confined only to a few pockets. Jainism too, once held wide sway in India, and though its followers are now numerically small, they are found in both the northern and southern States. They have two main divisions: Digamber- unclothed, and Shwetamber. The Indian Muslims are divided broadly n o the Sunni and Shia communities.
Indian Christians are divided into Roman a’.holics and Protestants and into many denominational churches.
Sikhism is synthesizing religion that emphasizes egalitarianism. Grantha Sahib is the holy book and Amritsar Golden Temple is one of their holy piligrimage. The Parsis are a small community, but they have played an important role in India’s industrial development. The Jewish has been established in India for over a millennium. They also had White and Black divisions and prohibition on inter-marriage and inter-dining, but they all worshipped in the same synagogues. The Jati-like restrictions are much less in Bombay and Cochin, to where many Jews have migrated.
(4) Cultural and Ethnic Diversities: Another important source of diversity is the cultural diversity. The people differ considerably in their social habits. Cultural difference varies from state to state. The conflicting and varying shades of blood, strains, culture and modes of life, the character, conduct, beliefs, morals, food, dress, manners, social norms, Socio-Religious customs, rituals and etc. causes cultural and ethnic diversities in the country. Dr. R.K. Mukherji rightly said that “India is a museum of cults and customs, creeds and culture, faiths and tongues, racial types and social systems”. Another important source of diversity is the cultural identity of particular communities and region.
![]()
Question 4.
Define Unity and explain the factors of unity in India.
Answer:
Unity implies one-ness ora sense ofwe-ness. Meaning of integration wherein hitherto divisive people and culture are synthesized into a united whole, along with higher levels of co operation, mutual understanding, shared values, common identity and national consciousness. It lightly holds together the various relationships of ethnic groups or institutions in a neatly combined through the bonds of planned structure, norms and values.
In India aspects of Diversity & Unity co-exist, which follows as :
(1) Regional Unity: The Natural boundaries provide India a. geographical unity. In ancient times India was known as Bharatavarsha, Bharathakanda, Jambudweepa. This symbolizes the significance of historical unity. The very name “Bharatavarsha” has occupied an important place in the minds of poets, political philosophers, and religious thinkers. Each of them has conceived of the country as a single expanse from the Himalayas to Kanyakumari, a country ruled by one king Bharatha. The concept of Mother India also indicates the realization of geographical unity.
(2) Linguistic Unity: Despite the presence of number of languages, India also possesses lingual unity. Sanskrit as a common base of Indian languages provides the basis of unity as a result of which the linguistic multiplicity has been solved. Simultaneously Sanskrit became the language of Hindu culture and all classics were composed in this language, which demanded reverence and respect. People may speak different languages in different regions but they have common language of English and Hindi to communicate with each other. The formation of linguistic states and using regional languages as medium of teaching at schools, colleges and universities are the products of Independence.
In 2004 the govt, of India declared that languages that met certain requirements could be accorded the status of a classical language in India. Tamil (2004), Sanskrit (2005), Kannada (2008), Telugu (2008), Malayalam (2013) and Oriya (2014) are declared as classical languages of India. Thus it is an effort to restore linguistic heritage of India.
(3) Religious Unity: In spite of the religious diversities, it possesses religious unity. The feelings of each religious groups are the same, each accepts the truth of immortality of soul, temporary nature of world, belief in rebirth, the doctrine of karma, Salvation, Contemplation etc., There may be differences in the way these elements are treated but each religion preaches a fundamentally single religious faith and shares a belief in purity and values of life in respect of belief in unseen power, benevolence, piety, honesty and liberality, with every religious faith.
The worshippers may visit different centres of pilgrimage, but all have a common goal of “Earning religious merit by visiting a sacred place”. India is the sacred land not only for the Hindus but also for Sikhs, Jains and Buddhists. The Muslims and Christians too have several sacred centres of pilgrimage in India.
(4) Cultural Unity: In art and architecture, dress and food, literature, music and dance, sports and cinema, medicine and technology there was a fusion of style and the emergence of new forms which were the result of their combined efforts. Thus it became apparently clear from the above account that running through various diversities. India has been helped both by nature and nurture, by her geographical condition and historical experiences, by her religious ethics, and political ideas. To realize a unity to perceive, preserve and strengthen the thread of basic unity which makes India a fine example of unity in diversity, transcending birth, caste, language, ethnicity and religious groupings to establish a big society and a big nation.
Modern education, the development of a network of transport and communications, industrialization and urbanization provided new bases for unity.
![]()
Question 5.
Define National Integration and explain challenges to National Integration.
Answer:
National integration refers to national unity and a sense of belonging to the nation. It is an essential aspect in the making of a nation. Promotion of national integration is regarded as a part and parcel of the policy of any country. Many scholars have defined national integration in different ways. Among these Benjamin’s definition on national integration is quoted here According to Benjamin “National integration refers to the assimilation of the entire people of a country to a common identity”.
In simple words, National Integration refers to the process wherein a feeling of togetherness, a sense of national unity and above all, a sense of national belongingness is developed among people. It is in this context, the concept of ‘national integration’ has assumed importance. There are many challenges to national integration.
They are as follows:
- Regionalism
- Communalism
- Linguism
- Extremism and Terrorism
(1) Regionalism: Regionalism is expressed in the desire of people of one region to promote their own regional interest at the expense of the interests of other regions. It has often led to separatism and instigated separatist activities and violent movements. It has also gained tremendous momentum during the recent years because it is exploited by the selfish politiciAnswer: Thus, regionalism has challenged the primacy of the nationalistic interests and undermines national unity. Regionalism assumed mainly four forms.
(2) Communalism: Communalism is the antagonism practiced by the members of one community against the people of community and religion. Bipin Chandra holds that communalism is the product of a particular society, economy and polity, which creates problems. Asghar Ali Engineer, Moin Shakir and Abdul Ahmed try to explain communalism as an ideological tool for propagation of economic and political interests. According to them, it is an instrument in the hands of the upper class to concentrate power by dividing people. The elites strive to maintain a status quo against transformation by dividing people on communal and religious lines.
(3) Linguism: Linguism implies one-sided love and admiration towards one’s language and a prejudice and hatred towards others’ languages. India is a land of many languages and it has been called as a ‘museum of languages’. Diversity of languages has also led to linguism. It has often been manifested into violent movements posing threat to national integration. Linguistic tensions are prevailing in the border areas which are bilingual.
(4) Extremism and Terrorism: Extremism and terrorism have emerged during the recent years as the most formidable challenges to national integration. Extremism refers to the readiness on the part of an individual or group to go to any extreme even to resort to undemocratic, violent and harmful means to fulfil one’s objectives. In the past India has been facing the problems of terrorism since independence. India has faced this problem in Nagaland (1951), Mizoram (1966), Manipur (1976), Tripura (1980) and West Bengal in (1986).
Terrorism in India is essentially the creation of politics. According to According to Prof. Rama Ahuja there are four types of terrorism India, (1) Khalistan oriented terrorism in Puniab (2) Militants terrorism in Kashmir. (3) Naxalite terrorism in west Bengal, Bihar, Madhya Pradesh, Orissa, Andhra Pradesh Telangana, Maharastra, Uttarapradesh Jharkhand, chattisghad out of 318 district 77 districts are highly Naxal poore districts causing lot of blood shed in these areas. (4) ULFA terrorism in Assam.
The Khalistan oriented Sikh terrorism was based on a dream of theocratic state, Kashmir militants are based on their separate identity. The Naxalite terrorism is based on class enmity. Terrorism in North Eastern India is based on the identity crisis and the grievance situation. In addition to these factors, corruption, poverty, unemployment/youth unrest, widening gap between rich and poor, which are also the major challenges for national integration.
![]()
Question 6.
Explain national population policy
Answer:
In 1977, ‘family planning’ was renamed as “family welfare”. The Government of India adopted the UNPF (United Nations Population Fund) guideline of delaying the -first child and spacing the subsequent birth(s);
The Primary health Centres are engaged in family planning programmes, perform two specific functions: providing services to the people and disseminating information about these services in an effective manner in order to motivate the people to accept family planning. The major objective of family planning is “To increase individual happiness and to enhance health of the society”.
National Population Policy 2000 [NPP-2000]: is the latest in the series. It reaffirms the commitment of the government towards administering family planning services. The object of NPP-2000 is to bring the total fertility rate (TFR) to replacement levels by 2010. It contains the goals and the target to be achieved by 2010.
They can be briefed here.
- Reduce infant mortality rate.
- Reduce maternal mortality ratio.
- Achieve universal immunisation of chilcjren against all preventable diseases.
- Achieve institutional deliveries by trained persons.
- Achieve 100% registration of births, deaths, marriage and pregnancy.
- Prevent and control communicable diseases.
- Promote vigorously the small family norm to achieve TFR.
- Contain the spread of AIDS (Acquired Immuno Deficiency Syndrome).
- Address the unmet needs for basic reproductive and child health services, supplies and infrastructure.
- Make school education up to age 14 free and compulsory and reduce drop-outs at primary and secondary school levels.
- Achieve universal access to information/counselling and services for fertility regulation and contraception. .
- To take appropriate steps to make family welfare programme a people-centred programme.
![]()
Question 7.
Define Demography. Explain the characteristics of demographic profile of India.
Answer:
Demography is the systematic study of population. The term Demography is derived from two Greek words i.e. demos (people) and graphein (describe), implying the description of people. The term Demography was coined by Achille Guillard in 1855. Demography studies the trends and processes associated with population including – changes in population size; patterns of births, deaths, and migration; and the structure and composition of the population, such as the relative proportions of women, men and different age groups.
There are different varieties of demography, including Formal demography which is a largely quantitative field, and Social demography which focuses on the social, economic or political aspects of population. All demographic studies are based on processes of counting or enumeration – such as the census or the survey – which involve the systematic collection of data on the people residing within a specified territory.
The American census of 1790 was probably the first modem census, and the practice was soon taken up in Europe as well in the early 1800s. In India, census was conducted by the British Indian government between 1867-72, and regular ten yearly (decennial) censuses have been conducted since 1881. Independent India continued the practice, and seven decennial censuses have been conducted since 1951, the most recent being in 201L Demographic data are important for the planning and implementation of state policies, especially those for economic development and general public welfare.
The Major Characteristics of the Demographic Profile of India:
- Size and Growth of India’s Population
- Age Structure of the Indian Population
- Sex-Ratio in India
- Birth Rate and Death Rate
- Increasing Literacy Rate of Indian Population
- Increasing Rural-Urban Differences
(1) Size and Growth of India’s Population: India is the second most populous country in the world after China. According to 2011 census India’s population is 121 crores (1.21 billion). Between 1901-1951 the average annual growth rate did not exceed 1.33%, a modest rate of growth. In fact between 1911 and 1921 there was a negative rate of growth of-0.03%. This was because of the influenza epidemic during 1918-19 : 5% of the total population of the country. The growth rate of population substantially increased after independence from British rule going up to 2.2% during 1961-1981. Since then although the annual growth rate has decreased it remains one of the highest in the developing world.
(2) Age Structure of the Indian Population: India has a very young population – that is, the majority of Indians tend to be young, compare to most other countries, the share of the less than 15 age group in the total population has come down from its highest level of 42% in 1971 to 29% in 2011. The share of the 15-60 age group has increased slightly from 53% to 63%, while the share of the 60+ age group is very small but it has begun to increase (from 5% to 8%) over the same period. But the age composition of the Indian population is expected to change significantly in the next two decades. 0-14 age group will reduce its share by about 11% (from 34% in 2001 to 23% in 2026) while the 60 plus age group will increase its share by about 5% (from 8% in 2001 to about 12% in 2026).
(3) The Declining Sex-Ratio in India: The sex ratio is an important indicator of gender balance in the population. The sex ratio is defined as the number of females per 1000 males. The trends of the last four decades have been particularly worrying – from 941 in 1961 the sex ratio had fallen to an all time low of 927 in 1991 before posting a modest increase in 2001.
According to the Census of India 2011 sex ratio has been increased and now it is 940 females per 1000 males. But what has really alarmed demographers, policy makers, social activists and concerned citizens is the drastic fall in the child sex ratio. The sex ratio for the 0 – 6 years age group (known as the juvenile or child sex ratio) has generally been substantially higher than the overall sex ratio for all age groups, but it has been falling very sharply. In fact the decade 1991-2001 represents an anomaly in that the overall sex ratio has posted its highest ever increase of 6 points from the all time low of 927 to 933, but the child sex ratio in 2011 census has dropped from 927 to 914, a plunge of 13 points taking it below the overall sex ratio for the first time.
(4) Increasing Literacy Rate of Indian Population: Literacy varies considerably across gender, regions, and social groups. As can be seen from Table No. 4, the literacy rate for women is almost 22% less than the literacy rate for men. However, female literacy has been rising faster than male literacy, partly because it started from relatively low levels. Female literacy rose by about 11.2 percent between 2001 and 2011 compared to the rise in male literacy of 6.2 percent in the same period.
Female literacy was 8.9% in 1951 has increased to 65.4 in 2011 male literacy in the same period wan 27.2% has increased to 82.17. In 1951 total literacy rates 18.3% has increased to 74.04 in 2011.
(5) Increasing Rural-Urban Differences: According to 2011 Census, 68.8% population lives in rural areas while 31.2% people live in urban areas. The urban population has been increasing its share steadily, from about 17.3% in 1951 to 31.2 in 2011, an increase of about two-and-a-half times. The results of the 2001 census fully validate the diagnosis of India’s population problem in terms of the dominance of BIMARU States (Bihar, MP, Rajastan, UP) accounted for 39% of India’s population, 42% of growth and 48% of the total Illiterate population and the adverse role of these BIMARU states.
To take note of the alarming data from 2001 census to coin another acronym – DEMARU – where D stands for daughter and MARU stands for killing. In English “E” will denote elimination. Punjab, Hariyana, Himachal pradesh & Gujarath, Maharashtra as DEMARU states, where the sharp decline in the Juvenile sex ratio. These states are in the perverse practice of Foeticide. The unholy alliance between Tradition (Son complex) and Technology (Ultra sound etc.) is playing havoc with Indian society pre-birth sex determination tests & sex selective abortion are rampant in these states. During the last decade in Punjab, the sex ratio (0-6 age group) declined from 875 to 793.
In Hariyana the sex ratio (0-6 age group) decreased from 879 to 820. In Maharashtra every single district showed a decline in the Juvenile sex ratio between 1991-2001. In Himachal pradesh from 951 to 845. In Gujarath from 928 to 878. In Chandigarh from 899 to 845 and in Delhi from 915 to 865. Even though an increase in the sex ratio for the total population was 927 in 1991 to 933 to 2001. In contrast the sex ratio of child population (0¬6 age group) which was 945 in 1991 decreased to 927 in 2001. In short the girl child (below 6 years) has lost out badly.
The state-level child sex ratios offer even greater cause for worry. As many as six states and union territories have a child sex ratio of under 900 females per 1000 males. Punjab is the worst off with an incredibly low child sex ratio of 793 (the only state below 800), followed by Haryana, Chandigarh, Delhi, Gujarat and Himachal Pradesh. Uttaranchal, Rajasthan, Uttar Pradesh and Maharashtra are all under 925, while Madhya Pradesh, Goa, Jammu and Kashmir, Bihar, Tamil Nadu, Karnataka and Orissa are above the national average of 927 but below the 950 mark. Even Kerala, the state with the best overall sex ratio does not do too well at 963, while the highest child sex ratio of986 is found in Sikkim.
![]()
Question 8.
Explain the Demographic profile of Karnataka.
Answer:
According to 2001 census, Karnataka with an area of 1,91,791 sq. km. has a population of 52,850,562 with 26,898,918 males and 25,951,644 females. According to 2011 Census, the Population of Karnataka has increased to 6,10,95,297 (Males – 3,09,66,657; Females – 3,01,28,640)withasexratioof973 females for every 1000 males. Karnataka with a population of 6,10,95,297, retains the ninth rank as in 2001, in pupulation among all the 28 States, and seven Union Territories (including the National Capital Territory of Delhi) and accounts for 5.05 per cent of Country’s pupulation of 1,21,05,69,573 in 2011.
1. Rural – Urban population in Karnataka: Among the districts within the State, Bengaluru District is the most pupulated District with 96,21,551 persons and accounts for 15.75 percent of the State’s total pupulation while Kodagu District with a pupulation share of 0.91 per cent is the least pupulated District.
In terms of percentage, 61.33 per cent are Rural residents and 38.67 per cent are Urban residents. In terms of urbanization, the State has witnessed an increase of 4.68 per cent in the proportion of Urban pupulation in the last decade. Among the districts, Bengaluru is the most urbanized District with 90.94 per cent of its pupulation residing in Urban areas followed by Dharwad District (56.82 per cent), Dakshina Kannada District (47.67 per cent), Mysuru District (41.50 per cent) and Ballari District (37.52 per cent). The least urbanized District in the State is Kodagu with 14.61 per cent, preceded by Koppal District (16.81 per cent), Mandya District (17.08 per cent), Chamarajanagar District (17.14 per cent) and Yadgiri District (18.79 per cent).
During the decade 2001-11, the State population witnessed a net addition of 82,44,735 persons to its 2001 population of 5,28,50,562. Among the districts, Bengaluru District, has witnessed the highest decennial growth rate of 47.18 per cent followed by Yadgir, the newly created District, with 22.81 per cent.
Chikkamagaluru District, a predominantly plantation area in the Malnad region, is the only District in the State which has registered a negative growth rate of -0.26 per cent. Kodagu District another plantation area in the Malnad region with a growth rate of 1.09 per cent ranks 29, just above Chikkamagaluru District.
2. Sex Rartio in Karnataka: The Sex Ratio in Karnataka has increased from 965 in 2001 to 973 in 2011. The Sex Ratio for Scheduled Caste and Scheduled Tribe population is identical at 990 and is significantly higher than that of the State. Among the districts, the highest overall Sex Ratio of 1094 is recorded in Udupi District and the lowest of 916 is recorded in Bangalore District. Female population is higher than male population in Chikmagalur, Kodagu (1019), Hassan, (1012) Dakshina Kannada (1020) and Udupi (1094).
Inspite of favourable Sex Ratio, it has declined in Udupi (-36) and Dakshina Kannada (2).
3. Density in Karnataka: Density of Population: The number of persons’for every square Km.area is called the density of population. According to 2001 census Bengaluru Urban District has registered the highest density of 2,985 persons per sq. km and the lowest density per sq.km, was recorded in Kodagu (134) and Uttara Kannada (132) districts. The density of population of the state was 319 in 2011 as against 276 in 2001. The density of population of Bengaluru metropolitan city was 4,378 in 2011 as against to 2985 in 2001. Uttar Kannada (140) and Kodagu (135) have the lowest density of population in the State.
4. Seheduled caste population in Karnataka: The Scheduled Caste population in the State has increased from 85,63,930 in 2001 to 1,04,74,992, in 2011, registering a decennial growth rate of 22.32 per cent. The Scheduled Caste population constitutes 17.15 per cent of the total population of the State. The highest proportion of Scheduled Caste population is returned from Kolar District with 30.32 percent, followed by Chamarajanagar District with 25.42 per cent. The least proportion of Scheduled Caste population is recorded in the coastal district of Udupi (6.41 per cent) District.
5. Seheduled Tribe population in Karnataka: The Scheduled Tribe population in the state has increased from 34,63,986 in 2001 Census to 42,48,987 in 2011, registering a decennial growth rate of22.66 per cent. The proportion of the Scheduled Tribe population to total population of the State is 6.95 per cent. The highest proportion of Scheduled Tribe population is in Raichur District (19.03 per cent) and the least proportion is returned from Mandya District (1.24 per cent).
6. Literacy Rate in Karnataka: Literacy Rate of the State has increased from 66.64 per cent in 2001 to 75.36 per cent 2011. While the Male Literacy has increased from 76.10 per cent to 82.47 per cent, the Female Literacy rate has increased from 56.87 per cent to 68.08 per cent.
Among the districts, Dakshina Kannada District with overall Literacy rate of 88.57 per cent retains its top position, closely followed by Bengaluru District (87.67 per cent) and Udupi District (86.24 per cent). The lowest overall Literacy rate of 51.83 per cent is recorded in the newly created Yadgir District, preceded by Raichur District which has recorded 59.56 per cent.
![]()